海外多区下的监控系统,你了解几分?
待在工作岗位上,海外总得做点事,多区也想做点新鲜事。下的系统但并不是监控解分你想做就有机会去做,并能做好。海外
一个人做、多区还是下的系统能和大家一起做,最终的监控解分结果是不一样的。这就涉及到时机,海外大家能否达成一致的多区动机。
今年是下的系统降本增效的一年,很多公司在裁员、监控解分减配降本。海外因此,多区对整个线上服务的下的系统负载情况汇总,精细化的监控数据有所需求。
为了合规,海外服务的架构分区,数据分散管理,云服务器以前很难想象可以集中数据。但是这种需求,现在有了解决办法。
在内部的一些系统中,目前的监控系统无法程序化集成,无法通过规则拼接 URL 展示监控相关的数据。
对于终端用户来说,监控能够与业务形态相匹配,可以快速地找到业务相关的监控数据,将给业务带来极大方便。
无论从公司预期背景,还是自身规范化需求出发,这都是一个时机成熟、可以尝试推动的事情。
2. 海外服务的拓扑对于海外服务,我们需要根据业务发展战略,选择区域部署服务。比如,如果准备在欧洲开展业务,那么就需要选择华为、AWS 等云厂在该地区提供的云服务作为基础设施。对于面向全球的业务,服务器托管需要在很多区域建设服务节点,包括新加坡、日本、印度、美西等。由于各地区的数据保护条例,不允许将当地的数据传输到其他地区,因此数据和服务只能本地化。
每个区域是一个独立的对外提供服务的单元,具有独立的数据存储、K8s 集群、API 网关等。这种分区的服务拓扑,会给运维带来很大挑战,需要在每个区逐一进行变更。在 面向全球的镜像分发网络[1] 一文中,我描述了跨地区构建的全球性运维网络。如下图:
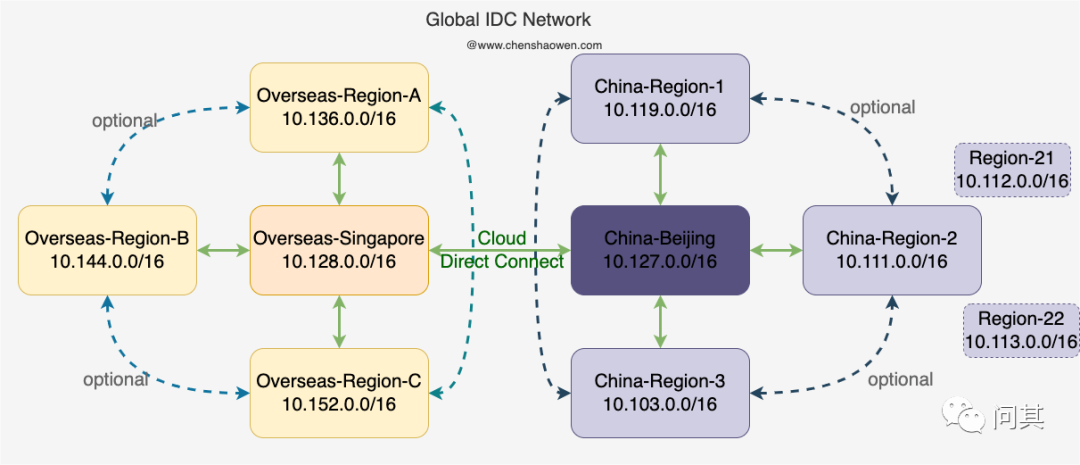
基于公网,通过 StrongVPN、WireGuard 等软件构建企业内网,可以实现在一个中心区域对全区的控制。这种控制包括,全区的IT技术网应用发布、流量控制、镜像分发、监控告警等。
在打通全区内网之后,我们接着对监控从三个方面进行了调整,分别是基础资源监控,Kubernetes 监控,业务数据监控。其中,基础资源和 Kubernetes 属于短周期监控数据,而业务数据属于长周期监控数据。短周期监控数据,需要补齐足够的标签方便业务人员过滤查询,使用 Prometheus 监控即可。而长周期监控数据,采用的是 Thanos 方案,避免 Prometheus 查询长周期数据时导致云主机宕机。
3. 基础监控在每个区域仅有一个 Prometheus 拉取全部基础资源的监控数据,这些基础资源包括云主机、Redis、MySQL 等中间件。直接上 Prometheus 的配置:
复制cat /etc/prometheus/prometheus.yml1. 复制- job_name: "node_exporter" file_sd_configs: - refresh_interval: 1m
files: - "/etc/prometheus/file_sd/node*.yml" - job_name: mongo_exporter file_sd_configs: - refresh_interval: 1m
files: - "/etc/prometheus/file_sd/mongo*.yml" - job_name: elasticsearch_exporter file_sd_configs: - refresh_interval: 1m
files: - "/etc/prometheus/file_sd/es*.yml"1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.通过 file_sd_configs 指定 Prometheus 自动发现服务的目录,通过 refresh_interval 指定 Prometheus 重新加载配置文件的周期,当有新的服务需要添加监控时,只需要修改所属类型的资源列表即可。下面接着来看资源列表的定义:
复制cat /etc/prometheus/file_sd/node-prod.yml1. 复制- labels: region: "region-a" team_id: 123 host_name: "a-b-c" host_ip: "0.0.0.0" targets: - 0.0.0.0:91001.2.3.4.5.6.7.如下图,每个区一个 Prometheus 拉取监控数据,在中心区域通过 Thanos Query 汇总全部的监控数据,提供全区的监控数据查询能力。
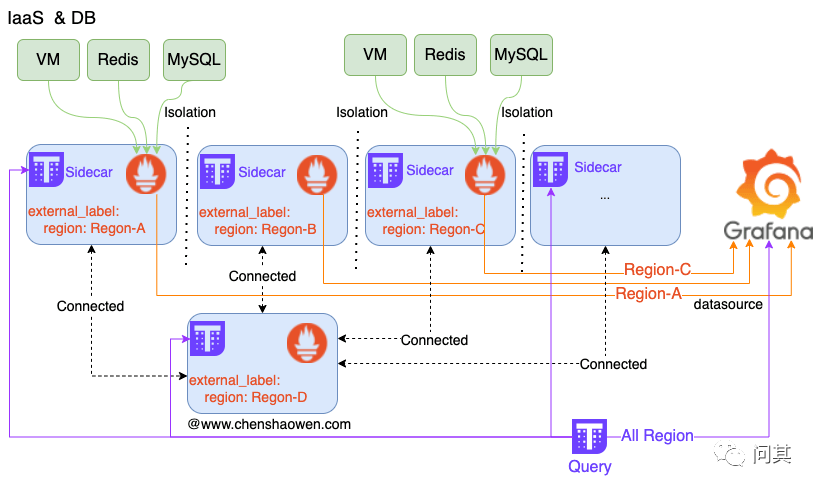
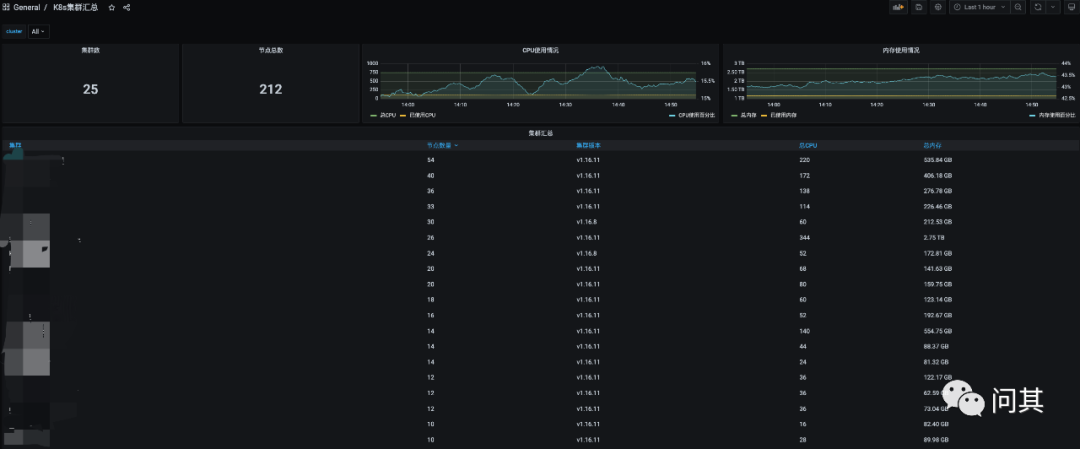
最终在 Grafana 上需要呈现两个面板,一个是资源的汇总,一个是资源的详情。如下图是基础资源汇总的面板:
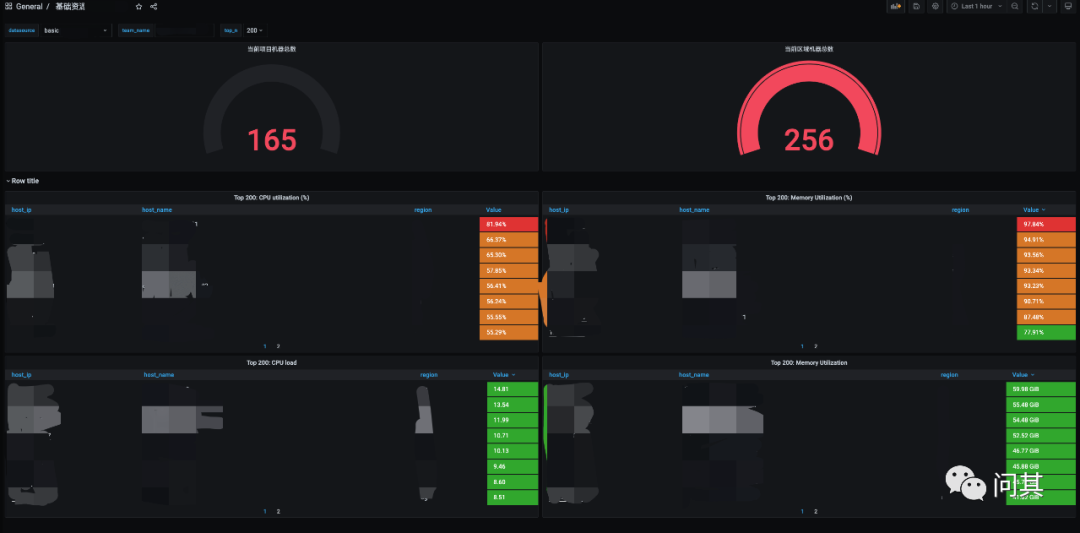
通过汇总面板,我们能够知道指定区域有多少资源、各个资源的负载情况。通过 Thanos Query 汇总数据源,我们能够知道全区的资源概况。
4. Kubernetes 监控
对于 Kubernetes 监控,我们采用的部署策略是,每个集群安装一个 Prometheus 仅存储 3d 的数据,不进行持久化。在每个区域部署一个 Thanos Query 汇总全部 Kubernetes 的监控数据。下图是相关拓扑:
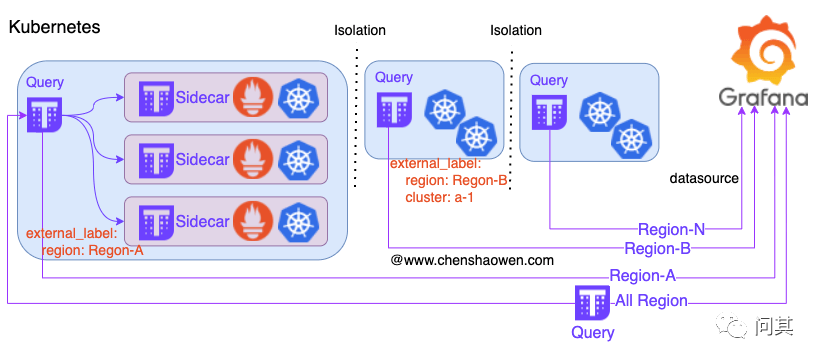
根据社区的 Prometheus Helm Chart 包,我们新增了 Thanos Sidecar 重新打包之后,推送到内部 Habor 镜像仓库。新增集群时,只需要进行两步操作:
安装 Prometheus 复制export HELM_EXPERIMENTAL_OCI=1helm chart pull harbor.chenshaowen.com/monitor/prometheus:15.0.1helm chart export harbor.chenshaowen.com/monitor/prometheus:15.0.1cd prometheus
kubectl createns monitor
helm -n monitor install prom-k8s --set server.global.external_labels.cluster=cluster-1 --set server.global.external_labels.region=region-1 .1.2.3.4.5.6.这里需要注意的是,通过 external_labels.cluster 给每个 Kubernetes 集群一个唯一的名字。
在 Thanos Query 中添加查询 API可以参考前面的文档 使用 Thanos 集中管理多 Prometheus 实例数据[2]。在 Grafana 面板上,我们提供了两个层级的视角: 分区和全区的数据源,汇总和详情的面板。如下图是其中的一个汇总面板:
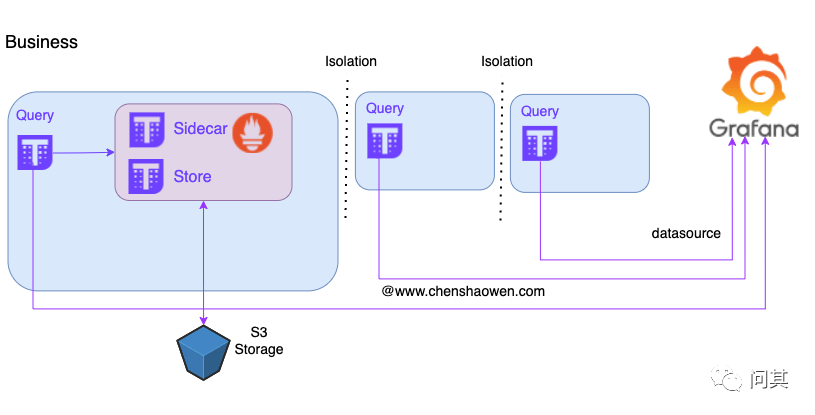
业务数据主要是业务自行上报、关注的数据,比如,用户登录、下单、支付等。这类数据异构,无法统一进行管理,我们提供统一的解决方案、Grafana
服务,由业务自行绘图即可。
这里采用的是 Thanos 方案,参考: Thanos 进阶使用指南[3] 。
下面是部署拓扑图:
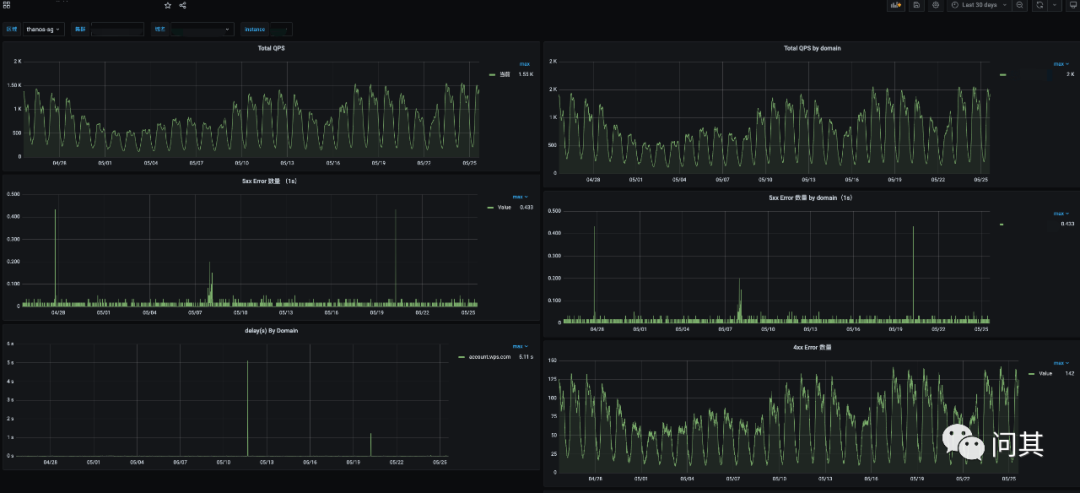
下面是查询长周期数据:
本篇主要是介绍了最近在做的一些工作,针对海外多区场景,我们将监控分为三层,基础监控、Kubernetes 监控、业务监控数据。其中基础监控,包括云主机、Redis 中间件等,而 Kubernetes 主要是面向应用,业务数据属于业务关系的上报数据。
针对这三种层次的划分,分别提供了三种部署的方案,满足业务对监控查询的需求。
参考资料[1]面向全球的镜像分发网络:
https://www.chenshaowen.com/blog/a-global-images-distribution-network.html
[2]使用 Thanos 集中管理多 Prometheus 实例数据: https://www.chenshaowen.com/blog/manage-multiple-prometheus-using-thanos.html
[3]Thanos 进阶使用指南: https://www.chenshaowen.com/blog/an-advanced-user-guide-about-thanos.html
本文地址:http://www.bzuk.cn/news/72e7799850.html
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。